
Benchmarking GraphQL solutions in the JS/TS landscape
We are definitely after GraphQL-hype these days. Articles with (valid) criticism are being published and professionals who understand the strengths of this technology use it to their advantage.
If you are in the latter group, you have to decide how you’d like to build your GraphQL stack. What are the pieces in the puzzle? What libraries to use?
This article focuses on the operational speed of those stacks.
Performance is important and can vary
I got to the benchmarking topic the same way as others before me - the solution I used was just slow and I was looking for answers and alternatives.
In GraphQL world we have a bunch of “primitives” like schema, models, resolvers or data-loaders so all solutions naturally have to gravitate around those. They will differ about some approaches but the core has to be similar because it has to solve similar problems.
If the things are similar, let the fastest win!
Pieces of the puzzle
It might be surprising but I identified 7 levels for the GraphQL stack. Some are optional but pretty common in mature projects so they should be taken into account.
Runtime environment
NodeJS is not the only JS runtime we can use on the server. There are alternatives and quite interesting ones with increasing popularity.
We will test:
- NodeJS
- Deno
- Bun

“Web library/framework”
The HTTP module in those environments is ok but too basic for many common things that servers have to do. That’s why we use libraries like:
- Express
- Fastify
- Koa

GraphQL library
Once we have a runtime for JS code and a nice way of handling the traffic, we need to start thinking about something that will handle the GraphQL requests.
Options are:
- Apollo Server
- Mercurius (for Fastify)
- GraphQL Yoga
- graphql-http

That’s not everything available on the market. For example, I was thinking about benchmarking benzene as well but I noticed the last activity in the repo to happen 2 years ago. Even if other solutions could rank high, I didn’t want to “recommend” something that I’m not sure if is still maintained.
Schema first vs code first
Most of those servers support both approaches - schema first and code first. After all, what the server cares about is the schema. Either provided (mostly) manually or fully dynamically generated. So theoretically it doesn’t feel like this should matter for the runtime but rather a bit for the build time or start time.
The common (modern?) approach is to use TypeScript and generate the schema from the types we already use in the project. This sounds smart, efficient, and shouldn’t affect the runtime speed.
Unfortunately, I found this to not to be true - the operation speed is affected for one of the solutions (that’s a spoiler 🙊):
What we will test is:
- type-graphql
- pothos

What is interesting about Pothos is that they state the following in the docs:
The core of Pothos adds 0 overhead at runtime
Almost as if it should be something that differentiates them from the other solution 😉
Optimising queries execution with graphql-jit
In the path of handling the GraphQL query, the server/engine has to parse the query and execute it against the schema.
graphql-jit optimises this process by compiling the queries into functions and memoizing them so the subsequent execution of the (cached) query is faster. That of course should shine very much in benchmarks that run the same query over and over again but production systems will see the benefits too as they receive the same queries frequently.
So let’s add another thing to the stack when possible:
- graphql-jit

Notes:
- GraphQL Yoga has "Parsing and Validation Caching” switched on by default. For a fair comparison, I also tested the performance of Yoga when opting out of it. In the results you’ll see those entries with
-no-pav-cachesuffix. But it’s not exactly the same asgraphql-jitso that variant was included as well with-jitsuffix. - I couldn’t make ApolloServer v4 working with
graphql-jit. I found a way to do it with v3 but theexecutorfunction was removed fromv4. Maybe some hacky solution could be done via Apollo Gateway to make it working but… I guess ApolloServer is somehow not interested in this solution and instead proposed other “performance techniques” like Server-Side Caching or Automatic Persisted Queries. Anyway, if interested, you can follow this issue on GH.
Observability
In non-hobby projects, it’s really worth investing in tools that will help us achieve observability of the system (see my colleagues talking about it). There are a bunch of solutions that are tied to specific vendors but I don’t want this to be a comparison of paid solutions so the only thing we are going to test here is:
- @opentelemetry

Frameworks
So far we were going from the bottom to the top. Adding more and more tools. But this strategy requires knowledge - you have to know what you need in the stack. I very much understand that for folks looking for “a GraphQL server for NodeJS” or “how to do GraphQL on the server” that’s not the natural way of going through this.
Folks new to the topic will rather look for a more rounded solution (and rightly so). In this spirit we will also give a test to the most popular JS backend framework:
- NestJS
Benchmarking
The repository with the benchmark is located here: https://github.com/tniezurawski/graphql-benchmarks
I must say I’m inspired by Ben Awad’s work, and he was inspired by Fastify’s benchmarks. I was thinking about contributing to Ben’s fork but it was quite out of date comparing to Fastify and I wanted to capture the current state. Whatever that means in terms of techniques, tools and libraries versions. I discovered some newer version of libraries don’t want to play together anymore. Like ApolloServer and JIT I mentioned earlier.
I also really wanted to give all runtime environments a try and see if any trends appear.
Feel free to contribute, and I’ll update this post.
Methodology
The plan is simple:
- Set up the server
- Run
autocannon:autocannon -c 100 -d 40 -p 10 localhost:3000/graphql
Autocannon fires requests agains the running server and gathers information about how fast it is. Here’s the explanation of arguments:
-c 100- 100 concurrent connections to the server. It simulates 100 users connecting to the server at the same time-d 40- the test will run for 40 seconds. I have a lot of cases to run, and following Fastify here. It should be enough to spot potential issues with memory leaks or the solution choking at a certain consistent load.-p 10- this is pipeplining factor. Each connection will send up to 10 requests in sequence, without waiting for responses in between. Useful to test throughput
The query is simplistic, yet, it will stress the solutions:
{authors {idfirstNamelastNamefullName # Resolver - string concatenationmd5 # Resolver - hashing functionbooks { # Async resolveridnamegenre}}}
Keep in mind that all the data is mocked. Even if we have to load data for books of the author, no XHR is made.
The dataset is small - 20 authors will be returned. The response has 486 lines of formatted JSON and is rather small.

The results
The fastest solution is 6x faster than the slowest!

The winner of this race is Fastify + Mercurius running on NodeJS with JIT switched on.
The difference is even more dramatic if we compare the first result that doesn’t use telemetry with the last result which does - then the first is almost 20x faster! 😮
Let’s dive in (tabular data available after hot takes).
Hot takes
If you need bite-sizes takes, here’s what is worth knowing:
- Environment:
- the results are quite unpredictable in my opinion. Some stacks work better on NodeJS, some with Bun, and some with Deno - do you see any correlation here that could explain this? I guess I know too little about differences between environments to draw any solid conclusion here.
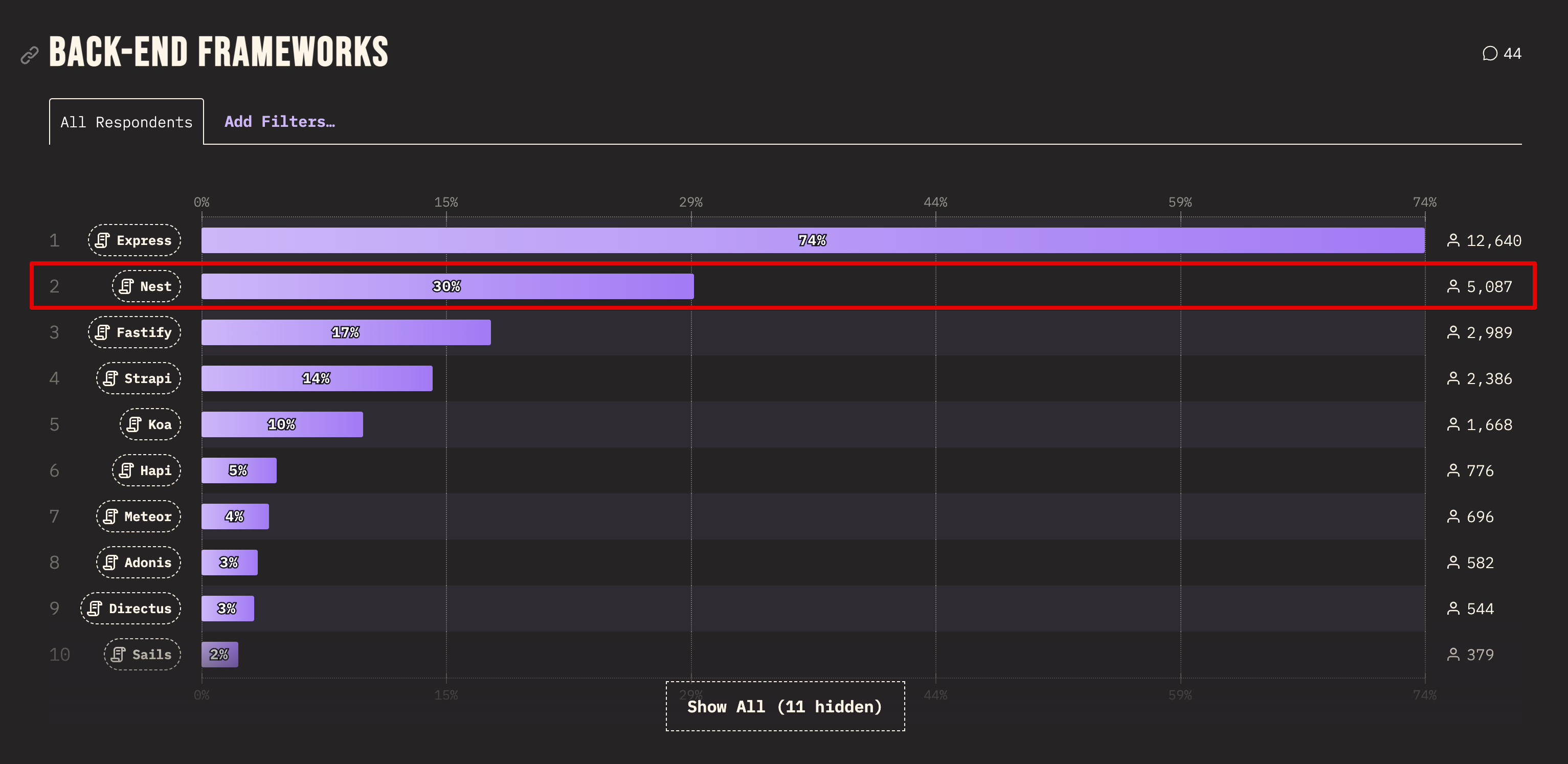
- “Web library/framework”:
fastifyis the fastest. Way ahead ofexpress- I’m not sure if
koashould be even a part of the comparison. I got a lot of errors of this kind when stressing the solution:
Error: write EPIPEat afterWriteDispatched (node:internal/stream_base_commons:159:15)at writevGeneric (node:internal/stream_base_commons:142:3)at Socket._writeGeneric (node:net:955:11)at Socket._writev (node:net:964:8)at doWrite (node:internal/streams/writable:596:12)at clearBuffer (node:internal/streams/writable:775:5)at Writable.uncork (node:internal/streams/writable:531:7)at ServerResponse.end (node:_http_outgoing:1141:19)at respond (--PATH--/graphql-benchmarks/node_modules/koa/lib/application.js:302:44)at handleResponse (--PATH--/graphql-benchmarks/node_modules/koa/lib/application.js:184:34)
To my understanding it fails under the heavy load of autocannon. It still was able to handle the traffic to some extend but I’m not sure of that result(s) and would stay away from Koa when using GraphQL. The errors were thrown for both koa-apollo and koa-graphql-api stacks.
- GraphQL library:
apollo-serveris the slowest and dragging down other techmercurius, together withfastifyis very fast
- JIT:
grapqhl-jit- every solution with JIT is faster and all the fastest solutions use it- having in mind the above, it’s really bad for ApolloServer to not support it 🤷♂️
- Schema first vs code first
- I’m surprised to learn that
type-graphqladds an overhead. Although, it is not super high and oscillate between 3% to 5%. Would you accept 3-5% performance drop to use types withtype-graphql? - Pothos on the other hand is responsible for ~1% of performance degradation so I think it might be just a noise in results. It very likely holds the promise of adding 0 overhead at runtime.
- I’m surprised to learn that
- Observability:
- gathering telemetry data is costly - as expected, but average drop of 80% speed for every solution is ridiculous!
- the issue is with gathering data about resolvers
- not tracking trivial resolver spans (results with
-itrssuffix) makes it a bit better - whenever a field is returned 1:1 without a function involved then we don’t track it. TBH, not much interesting info there and from my experience you’ll see those spans being “resolver” in1ms - not tracking resolver spans in general (results with
-irssuffix) is a big deal - when you stop tracking resolvers, you will observe a drop of about 13% performance speed. - so not tracking resolvers seems to be a must otherwise, who can accept 80% slowdown?
- gathering telemetry data is costly - as expected, but average drop of 80% speed for every solution is ridiculous!
- Frameworks:
- If you follow NestJS tutorial on building GraphQL server you’ll end up with express and ApolloServer which is the slowest solution here
- Even the absolute killer solution (
fastify-mercurius-jit) is dragged down by NestJS and sees 40% decrease in performance - I debugged the framework and I see two bottlenecks. One of them can be mitigated by not using
@Parent()decorator in resolvers but the other is unavoidable as it touches resolvers themselves. “Deparentification” accounts for almost 30% performance boost. So it’s definitely worth doing. But it’s a pity that the poor performance of@Parent()is not documented properly.
- Absolute values of latency:
- Comparing requests per second is important but have in mind the absolute values of latency. The slowest solution with telemetry needs 526ms to process a request without any calls being done to DB or external/internal services! That's very bad.
In a table
| Stack (all 45) | Requests/s | Latency (ms) | Throughput/Mb |
|---|---|---|---|
| nodejs-fastify-mercurius-jit | 12754.2 | 77.8 | 110.2 |
| nodejs-fastify-mercurius-pothos-jit | 12433.2 | 79.8 | 107.5 |
| deno-yoga-jit | 12092.0 | 82.1 | 104.2 |
| bun-fastify-mercurius-jit | 11745.8 | 84.6 | 101.0 |
| bun-yoga-jit | 11057.8 | 89.8 | 95.0 |
| nodejs-yoga-jit | 10941.2 | 90.8 | 94.5 |
| nodejs-fastify-mercurius-type-graphql-jit | 9991.8 | 99.5 | 86.3 |
| nodejs-nestjs-fastify-mercurius-jit-deparentification | 9904.6 | 100.3 | 85.6 |
| deno-fastify-mercurius-jit | 9608.6 | 103.5 | 82.8 |
| nodejs-nestjs-fastify-mercurius-jit | 7679.1 | 129.5 | 66.4 |
| bun-yoga | 7501.2 | 132.6 | 64.5 |
| bun-fastify-mercurius | 6784.0 | 146.7 | 58.3 |
| nodejs-express-yoga-jit | 6765.6 | 147.0 | 58.8 |
| nodejs-fastify-mercurius | 5786.2 | 172.0 | 50.0 |
| deno-yoga | 5773.2 | 172.4 | 49.8 |
| nodejs-fastify-mercurius-pothos | 5712.1 | 174.2 | 49.4 |
| nodejs-fastify-mercurius-type-graphql | 5472.2 | 181.9 | 47.3 |
| nodejs-yoga | 5443.6 | 182.8 | 47.0 |
| nodejs-yoga-type-graphql | 5332.6 | 186.6 | 46.1 |
| bun-graphql-http | 5319.1 | 187.1 | 45.7 |
| nodejs-fastify-mercurius-open-telemetry-irs | 4976.9 | 199.0 | 43.0 |
| deno-fastify-mercurius | 4828.4 | 206.1 | 41.6 |
| nodejs-express-yoga | 4352.3 | 224.1 | 37.8 |
| nodejs-express-yoga-pothos | 4124.5 | 235.2 | 35.9 |
| nodejs-koa-graphql-api | 3925.4 | 245.2 | 33.9 |
| nodejs-nestjs-fastify-mercurius | 3915.6 | 245.8 | 33.8 |
| nodejs-yoga-no-pav-cache | 3913.3 | 246.0 | 33.8 |
| nodejs-graphql-http | 3843.1 | 249.8 | 33.3 |
| nodejs-express-yoga-type-graphql | 3625.2 | 262.7 | 31.5 |
| nodejs-graphql-http-type-graphql | 3580.5 | 266.8 | 31.0 |
| nodejs-express-graphql-http | 3157.2 | 293.7 | 27.4 |
| nodejs-express-graphql-http-type-graphql | 3037.1 | 300.4 | 26.4 |
| nodejs-koa-apollo | 2963.5 | 304.4 | 25.8 |
| nodejs-fastify-mercurius-open-telemetry-itrs | 2772.8 | 314.5 | 24.0 |
| nodejs-express-yoga-no-pav-cache | 2629.1 | 319.2 | 22.9 |
| nodejs-express-apollo | 2612.8 | 321.2 | 22.9 |
| nodejs-express-apollo-pothos | 2587.5 | 323.4 | 22.7 |
| nodejs-express-apollo-type-graphql | 2478.8 | 316.6 | 21.7 |
| nodejs-nestjs-fastify-apollo | 2467.7 | 311.0 | 21.4 |
| nodejs-express-apollo-open-telemetry-irs | 2313.2 | 301.0 | 20.3 |
| nodejs-nestjs-express-apollo | 2095.5 | 299.1 | 18.3 |
| nodejs-nestjs-express-apollo-open-telemetry | 1553.0 | 377.3 | 13.6 |
| nodejs-fastify-mercurius-open-telemetry | 751.6 | 462.8 | 6.5 |
| nodejs-express-apollo-open-telemetry-itrs | 648.4 | 535.7 | 5.7 |
| nodejs-express-apollo-open-telemetry | 641.5 | 526.3 | 5.6 |
Conclusions
No matter if you use a framework like NestJS, or not, fastify, mercurius and graphql-jit should be your choice.
When gathering telemetry data, don't run on defaults, switch off resolvers tracking and switch it on only when you really
have to dive into some issues.
Best of luck!
If you'd like to see more content like this, please follow me on Twitter: tomekdev_. I usually write about interfaces in the real life. So where the design meets implementation.
Comments and discussion welcomed in this thread.